
Mining OpenVAS Knowledge
Vulnerability scanners like OpenVAS are an integral part of many security monitoring operations. OpenVAS produces reports that contain a ton of precious information about a networking environment. In fact, if you use OpenVAS you probably know more about your network than you realize. Not only does it reveal security vulnerabilities, it also provides information about installed operating systems, applications, application versions and SSL/TLS certificates installed on your servers. It identifies open networking ports, network routers, and more.
There are several challenges to using this information effectively. Firstly, extracting all of that information from the scan reports is tricky. OpenVAS features a vast array of scanning plugins, old ones and newer ones. Various plugins represent the same type of information in different ways. For example, older plugins use a kind of text markup to tag certain information, like this:
cvss_base_vector=AV:N/AC:M/Au:N/C:N/I:N/A:N|summary=The remote HTTPS Server is missing the 'preload' attribute in the HSTS header.|solution=Submit the domain to the 'HSTS preload list' and add the 'preload' attribute to the HSTS header.|qod_type=remote_banner|solution_type=Workaround
Newer plugins may place that same information in dedicated XML tags, like this:
<solution-type>Workaround</solution-type>
Integrating the information in your security operations is also challenging due to the many different types of data. When a possible security incident is detected on your network, having the proper context for triaging it is crucial. You may want to correlate the incident details with OpenVAS information to get a richer context for analysis.
In larger networking environments multiple vulnerability scanners may be setup in various network segments. In that case it is useful to integrate the outputs of all scanners into a single consistent data set.
Knowledge
Now imagine that computers could read and understand OpenVAS scan reports like a security expert can. The machine would know where to find the various types of information, understand the significance of that information for your security operations, autonomously correlate the information to arbitrary other security data and reason about it.
This is what the EDXML transcoder for OpenVAS is intended for. While you can read all about EDXML here, in this post I will zoom in on this specific application and show how machines can learn about your network by reasoning about OpenVAS data.
EDXML enables transforming data into stories that machines can read, similar to how humans read a novel. By integrating expert knowledge about the data into the data itself, machines can learn what the data is telling, simply by reading it. This expert knowledge can be visualized, showing how machines "think" about the data. This is what I intend do in this post. We all love pictures, right? First though, let us install the EDXML transcoder:
What an EDXML transcoder does is take some kind of data as input (OpenVAS reports in this case), add expert knowledge to it and output the result as EDXML data. Besides generating EDXML transcoders can also express their knowledge as English text and as pictures. Since I promised pictures we will focus on those.
Expert knowledge can be used to construct inference pathways, which are associative reasoning steps that machines can take to discover knowledge contained in the data set. We can view these pathways by asking the transcoder to dump its concept graph:
This results in a file named "concepts.png" being written. Let us have a look at the full picture first (click for high resolution version):
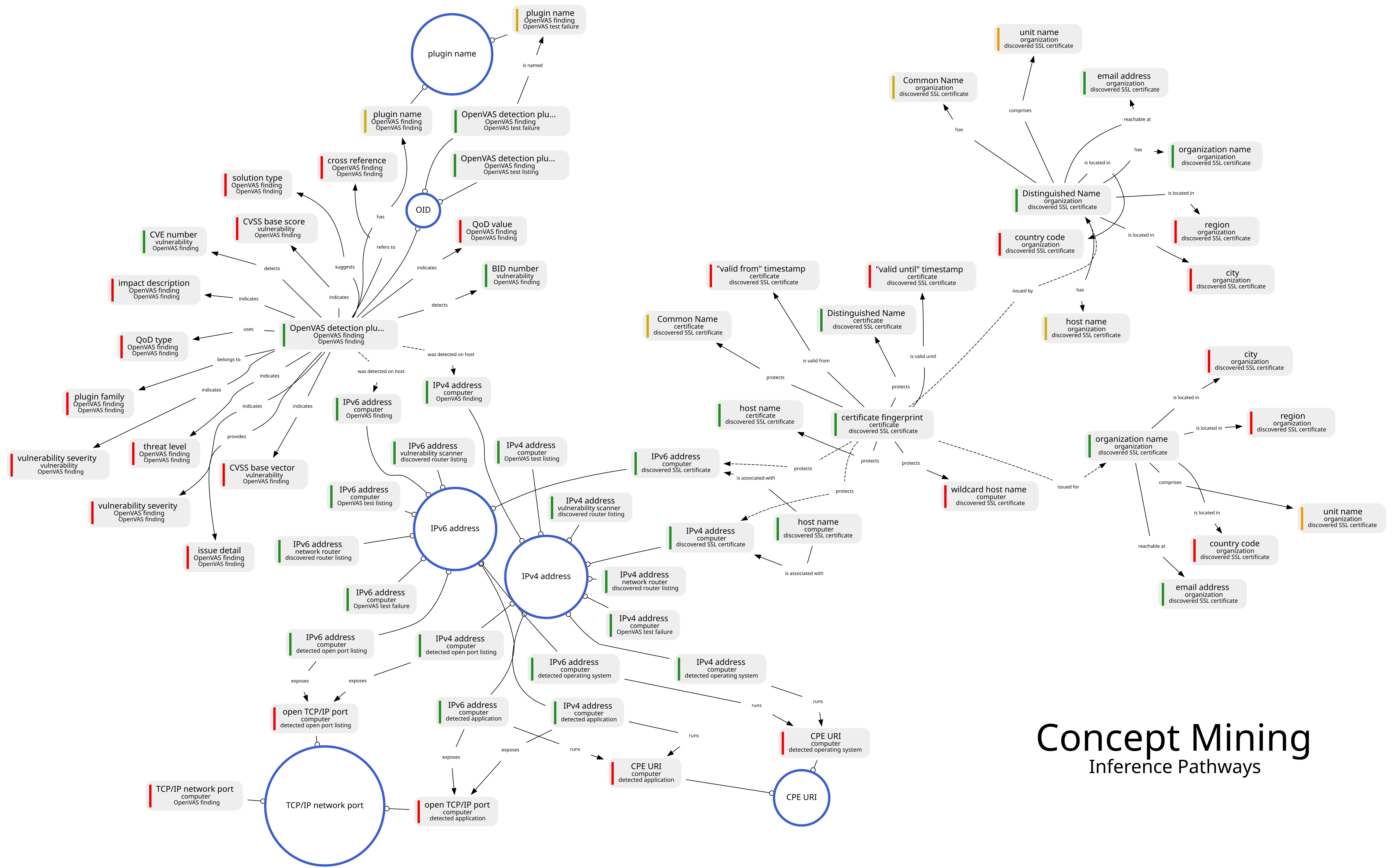
So, what are we looking at here? Well, in order to explain that we need to know some basics about EDXML concepts first.
Concepts
As part of its expert knowledge an EDXML transcoder can define concepts. You can think of concepts as the characters in the story that the data is telling. The OpenVAS transcoder defines concepts like "computer", "certificate", "OpenVAS finding", and so on.
The thing with concepts is that their information is scattered about in various parts of the data. For example, one might define a "computer" concept which may have an IP address, an operating system and open ports. In EDXML we call these things concept attributes. The various attributes of a particular computer may be found by different OpenVAS plugins, ending up in different parts of the scan report. In order to obtain all available knowledge about a computer, this information needs to be correlated and combined somehow. This is what concepts are for. Concepts teach machines how to correlate bits of information from various places.
Let us take things one step further. Various types of concepts may be related to one another. For example, a computer may be related to a certificate that is installed on that computer. That certificate may be related to the organization that issued it. The organization may in turn be related to multiple other certificates issued by it.
As you can imagine there are thousands of ways to correlate OpenVAS data to itself, let alone to other types of security data. Which correlations are relevant depends on the use case. Rather than manually programming all of these correlations into applications, EDXML enables machines to learn to perform these correlations on their own, based on the expert knowledge contained in the data and the needs of the end user. It can literally find its way in the data.
Concept Mining
Let us take a look at a detail from the full picture (again, click for high resolution version):
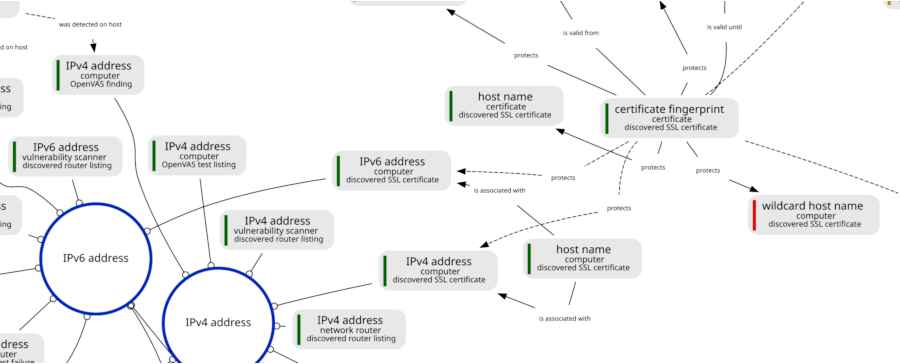
Now let's talk about gray boxes. Why? Because gray boxes are interesting. The light gray boxes shown above are concept attributes. We see attributes like IP addresses and host names. Each attribute is associated with a specific concept, which is displayed right below the attribute name. We see concepts like "computer", "certificate" and "network router".
The attributes are connected by means of concept relations. Combined, these relations form a graph containing inference pathways. Machines can use relations to take small reasoning steps to associate one piece of information with another. For example, we can see a relation between an IP address and a host name, both attributes of the "computer" concept. This is an example of an intra-concept relation. Relations of this type, depicted as solid lines, expand the knowledge about a concept by associating with another attribute of the same concept. In this case a machine can use the relation to find the IP address of a computer given its host name or the other way around.
We can also see dotted lines, like the relation between a certificate fingerprint and an IP address. This is an example of an inter-concept relation. Rather than expanding knowledge about a concept, these relations associate one concept to another. Machines can use these to discover networks of related concepts.
This process of extracting concepts from EDXML data is called concept mining.
Reasoning
So now we have seen what the inference pathways produced by the OpenVAS transcoder look like. In order to understand how these pathways are used to do the actual reasoning it is important to realize that the EDXML data itself does not look anything like a graph. The structure of EDXML data is actually really simple. It is made up of events, which are basically just sets of key / value pairs.
A transcoder may define multiple types of events. In this case, there is an event type representing an OpenVAS finding, an event type representing an operating system detection, and so on. The events are not explicitly related in any way. Only when the events are combined with the expert knowledge, which is contained in the same EDXML document as the events, the global structure is revealed.
The event type associates each event with expert knowledge. We can see this in the inference pathway visualizations. Each concept attribute specifies its associated event type, written at the bottom of the gray box. We see event types like "discovered SSL certificate" and "discovered router listing".
Now, given an EDXML event we can associate possible reasoning steps with it. For example, given a "discovered SSL certificate" event we can see that there is an inter-concept relation (dotted) between the "certificate fingerprint" and "IPv4 address" attributes of that type of event. This implies that the event contains information about a certificate and a computer and that these are related. This is an example of a reasoning step within the scope of a single event.
EDXML Concept Mining is an iterative process where the computer takes reasoning steps from a particular starting point. For example, we might specify an IP address as starting point and the computer may find an event containing that IP address. Then, by looking up the reasoning steps that have an IP address as starting point, it might associate a host name with the IP address. Then, the process repeats taking the discovered host name as a starting point, jumping from one piece of information to the next.
Reasoning steps can also jump from one event to another. For example, there may be many events that refer to the same IPv4 address, suggesting that these events may all provide information about a single host. In the inference pathways visualization this is represented by the blue circles. These circles are surrounded by concept attributes that share a common type of data. These are "reasoning hubs" that can be used to go from one event to another in search of more related information about a particular concept.
Let us take a look at another detail from the full picture:
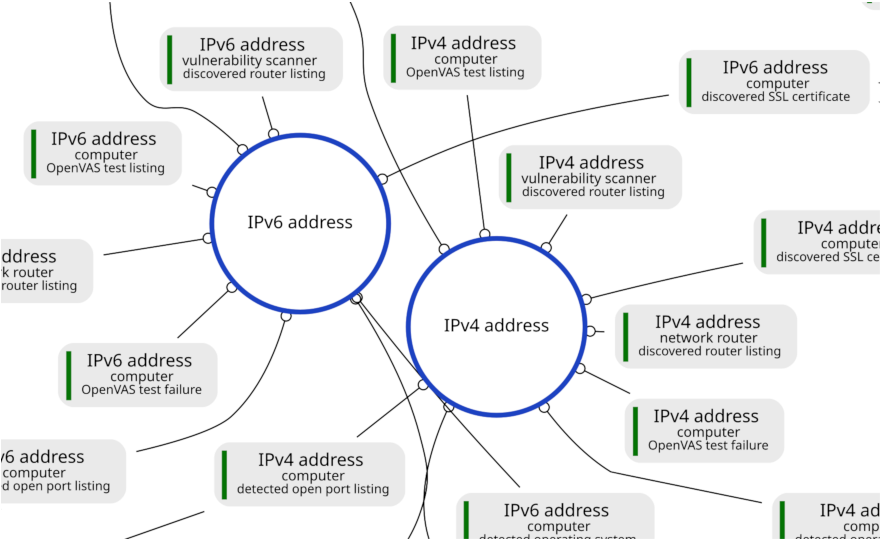
The above detail shows two reasoning hubs, one for IPv4 addresses and one for IPv6 addresses. As you can see, the hubs connect attributes from multiple event types. Note that the concepts of these attributes differ. For example, we can jump from the IPv4 address of a "computer" in one event to that same IPv4 address in another event where it belongs to a "network router". This is an example of a reasoning step that results in concept specialization. The reasoning step enables machines to use OpenVAS data to discover that a particular "computer" is actually a "network router".
When using the concept mining utility from the EDXML SDK on the output of the OpenVAS transcoder, we can see this in action. So, let us grab an OpenVAS XML report and use the transcoder to convert it into an EDXML document:
openvas-edxml --desc "My scan" --uri "/some/source/uri/" -f report.xml > report.edxml
Now we take the EDXML document and mine it:
edxml-mine --tell -f report.xml
On the terminal, we might see something like this scroll by:
Found a computer: '10.32.0.1'
Discovery: this computer is a network router.
Found attribute: '10.32.0.1' (IPv4 address) runs 'cpe:/o:checkpoint:gaia_os' (CPE URI)
Found attribute: '10.32.0.1' (IPv4 address) exposes '80/TCP' (open port)
Found attribute: '10.32.0.1' (IPv4 address) exposes '443/TCP' (open port)
The process of associating pieces of related data to form an "image" of a particular concept is similar to the way humans put together jigsaw puzzles. This analogy is used to explain EDXML concept mining in more detail here. More in depth information about concept mining algorithms can be found in this post.
Conclusion
Hopefully I managed to get you a coarse idea of how machines can mine knowledge from OpenVAS data. The visualized inference pathways are a nice way to illustrate how this works. When developing EDXML transcoders generating a picture is also valuable. It is a great way to see the expert knowledge you put in and check for bugs. Because, while the EDXML SDK can check if your transcoder is valid, it cannot check if the expert knowledge makes any sense. That is up to the expert.